关于CVPR2021,VQA2VLN的tutorial的总结
tutorial原地址:CVPR 2021 Tutorial on “From VQA to VLN: Recent Advances in Vision-and-Language Research”,本笔记总结一下在ppt里展示的VLN任务的内容,几位演讲者的视频还没看,毕竟有ppt和论文,概念理解应该不会有偏差
Background
浏览了一下,VLN其实是算一个在人机交互大背景下的Visual+Language的研究方向,其实和之前做的三维重建+导航有点关系,总而言之是2D和3D视觉方面的东西,下面稍微总结了下,后几个ppt还没看完,后面会追加该方向的论文链接和相关内容
See, Communicate, Act
机器模拟人的几种模拟方式,基本是将机器在看(视觉)、交流(文本)、行动几种模式下提高智能化,现在在See和Communicate两种模式的比较有代表性领域就是Computer Vision和Nature Language Processing,还有视觉和自然语言相结合的领域,例如Image-Understanding任务。前几年利用视觉和自然语言实现的智能化是从比较独立的模块获取的信息,比如目标检测,获取物体在图像上的(位置, 类别),给机器做一些什么任务,比如统计xx,预测人流量等。目前用结合See-Communicate(Vision-Language)的发展比较好的方向有VQA, Captioning,Text2Image Generation等。
- 会议上提到的这个VLN领域的理念是Connecting Vision and Language to Actions, 将vision(2D,3D)、language和(行动/指令)联系起来,理解复杂场景,并对输入请求做出具体行动,相当于是Video Understanding下的子任务。
Embodied AI

“Embodied AI is the field for solving AI problems for virtual robots that can move, see, speak, and interact in the virtual world.” 这是在page里的一个引言,关于实体AI(暂译),就是让机器获得 视听说、行动、理解几种功能,集成算法达到一个接近人一样的智能体,从Internet AI 过渡到 Embodied AI,甚至是给AGI,Artificial General Intelligence打基础,有一个关于Embodied AI的survey:
Duan et al., A survey of Embodied AI: From simulators to Research Tasks, 2021
Vision-Language Navigation
VLN是2018年提出的一个研究领域,当时的子标题是Vision-and-Language Navigation: Interpreting visually-grounded navigation instructions in real environments:在现实环境下,让机器理解基于视觉定位的导航指令。

左下是人为给出的指令
通俗来讲VLN任务就是为了给机器人导航,有两个任务:
①如何理解现实场景
②对于给出的Instructions,如何理解并做出行动
与3D视觉导航的区别(如自动驾驶使用的视觉SLAM、Radar等)
- 3D-Navigation : SLAM下从图像帧中处理得到点云判别障碍物、方位
- Sensor-Navigation : 传感器获取的空间信息(Radar、Lidar等) ,判别障碍物、方位
SLAM —> PointCloud —> direction
Sensor —> Mesh —> direction - VL-Navigation : Agent(摄像头)获取的视频信息,理解场景内容,并对指令做出行动,目前主要是在室内场景下研究导航任务
与VQA的区别
VLN相对增加了动态视觉(相机运动)、长文本、测试集和训练集上的领域差距
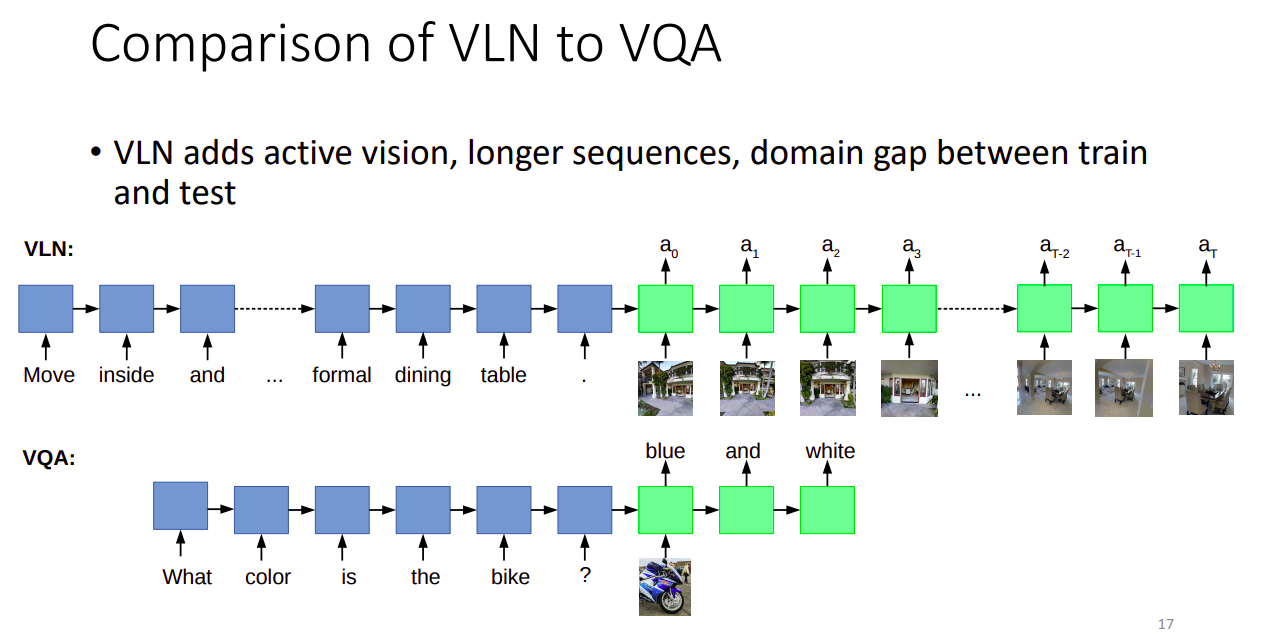
domain gap指的是比如在室内场景下训练,在室外场景测试,效果可能就急剧下降,并且一个训练样本就可以是整个场景,(比如浙江大学的3D重建方法,NeuralRecon所用的Scannet数据)
Indoor VLN
目前VLN主要是研究室内的导航任务,
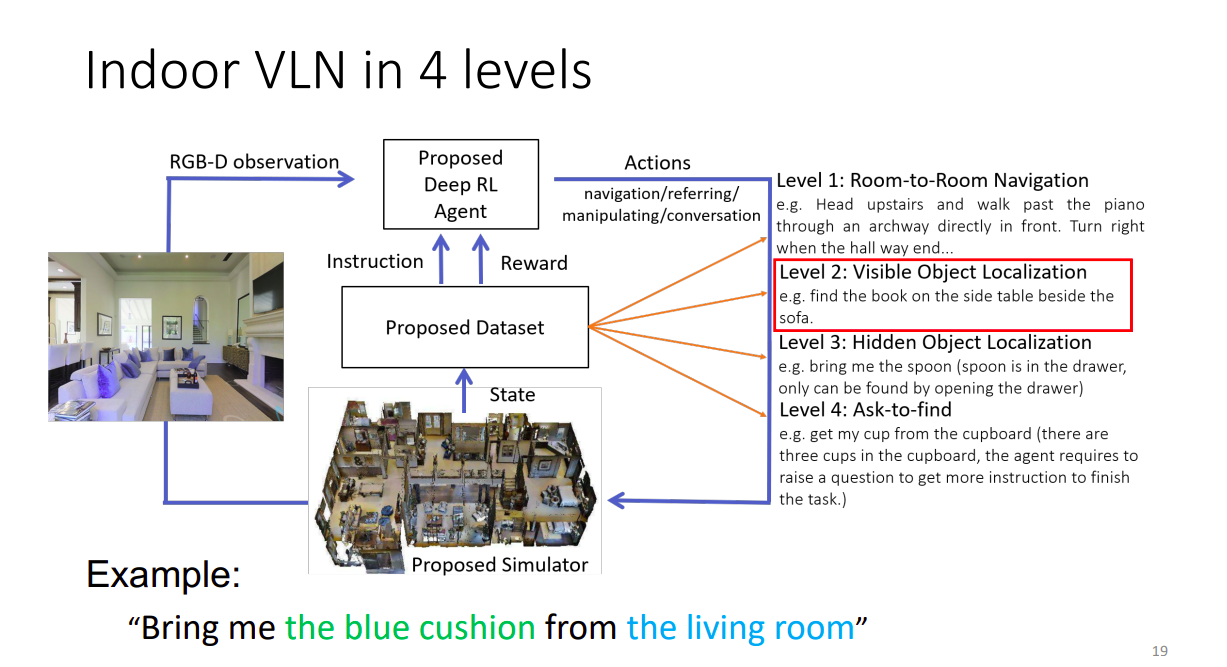
室内导航任务的几种指令难度等级
1. A到B的位移
2.找东西(可见)
3.找东西(不可见)
4.向人有针对性的提问得到更详细的信息,用这些追加的信息找东西
Indoor VLN Challenges
Significant Appearance Variation,同一种物体有不同外观

Rich Linguistic Phenomena,丰富的语境

Less Words, More Contents,文本所能表达的东西太少

VLN Models
- Seq2seq (a golden baseline)
• Speaker-follower - Attention Mechanism (something must try)
• EnvDrop, Self-monitoring, OAAM - Transformer (this is all you need)
• PREVALENT, Recurrent-Bert - Reinforcement Learning (Add-on)
• RCM, Soft Expert
Datasets
R2R 在214服务器上生成好了,从matterport模拟器得到的R2R任务 path distance 等
CVDN
NDH

