questions
mysql分为哪些层,各用来干嘛的

- mysql架构共分为两层:Server 层和存储引擎层
- Server 层负责建立连接、分析和执行 SQL
- 存储引擎层负责数据的存储和提取
为什么mysql用b+树而不是用b树:查询性能和顺序遍历的效率高
主要的原因可能就是b+数据存在叶子节点上,并且用指针连着,如果要遍历直接去扫一遍,而b树的话,需要遍历整棵树才能读完;
并且查找时,b+树高度一般很稳定,b树高度一般来说会更高,因为两者的mysql基于什么协议传输
TCP。
三次握手建立后,连接器验证用户名和密码。
连接器作用
- TCP三次握手
- 校检用户名密码,返回用户权限
查询缓存作用
- select语句输入,执行,先去查询缓存中找,查询缓存中存的是之前执行过的sql语句,以key-value保存的,底层数据结构为哈希表。
- 8.0.3后移除了这一层,在一些问题,包括性能问题、锁的竞争问题以及难以扩展。
解析器作用
词法分析-语法分析-语法树结构- 词法分析(Lexical Analysis)
- 语法分析(Syntax Analysis)语法分析器会将其转化为一个抽象语法树(AST)
- AST的作用:编译器或解释器用来理解代码含义的数据结构,它可以被后续的步骤用来进行语义分析、优化和生成目标代码等。
- 【查询优化】:对AST进行查询优化,选择合适的索引和决定连接顺序
【面试题】执行一条 SQL 查询语句,期间发生了什么?
- 连接器:建立连接,管理连接、校验用户身份;
- 查询缓存:查询语句如果命中查询缓存则直接返回,否则继续往下执行。MySQL 8.0 已删除该模块;
- 解析 SQL,通过解析器对 SQL 查询语句进行词法分析、语法分析,然后构建语法树,方便后续模块读取表名、字段、语句类型;
- 执行 SQL:执行 SQL 共有三个阶段:
- prepare 预处理阶段:检查表或字段是否存在;将 select * 中的 * 符号扩展为表上的所有列。
- optimize 优化阶段:基于查询成本的考虑, 选择查询成本最小的执行计划;
- execute 执行阶段:根据执行计划执行 SQL 查询语句,从存储引擎读取记录,返回给客户端;
如何查看我的sql被几个客户端链接了
show processlist;会有ID user host等字段
mysql推荐使用长链接,但会产生的问题:
随着长连接一直不释放,内存占用大。【解决方式】定期释放,主动重置连接mysql_reset_connection()
MYSQL的数据存储方式
- show variable like ‘datadir’; 可以查找mysql的文件在哪
1
2
3db.opt 用来存储当前数据库的默认字符集和字符校验规则。
t_order.frm 存放表结构,在 MySQL 中建立一张表都会生成一个.frm 文件,该文件是用来保存每个表的元数据信息的,主要包含表结构定义。
t_order.ibd 存放表数据。表数据既可以存在共享表空间文件(文件名:ibdata1)里,也可以存放在独占表空间文件(文件名:表名字.ibd)。
表空间文件的结构
表空间由段(segment)、区(extent)、页(page)、行(row)组成

- 表中的数据在Page里,数据是按「页」为单位来读写的,当需要读一条记录的时候,并不是将这个行记录从磁盘读出来,而是以页为单位,将其整体读入内存。
- 默认每个页的大小为 16KB,也就是最多能保证 16KB 的连续存储空间
按区分配空间的情况
- 在表中数据量大的时候,为某个索引分配空间的时候就不再按照页为单位分配了,而是按照区(extent)为单位分配。每个区的大小为 1MB,对于 16KB 的页来说,连续的 64 个页会被划为一个区,这样就使得链表中相邻的页的物理位置也相邻,就能使用顺序 I/O 了。
段一般分为数据段、索引段和回滚段等。
- 索引段:存放 B + 树的非叶子节点的区的集合;
- 数据段:存放 B + 树的叶子节点的区的集合;
- 回滚段:存放的是回滚数据的区的集合,之前讲事务隔离 (opens new window)的时候就介绍到了 MVCC 利用了回滚段实现了多版本查询数据。
Innodb的行格式
InnoDB 提供了 4 种行格式,分别是 Redundant、Compact、Dynamic和 Compressed 行格式。
COMPACT 行格式

数据类型:char 是定长的,varchar 是变长的,变长字段实际存储的数据的长度(大小)不固定的。
row_id:
如果我们建表的时候指定了主键或者唯一约束列,那么就没有 row_id 隐藏字段了。如果既没有指定主键,又没有唯一约束,那么 InnoDB 就会为记录添加 row_id 隐藏字段。row_id不是必需的,占用 6 个字节。trx_id:
事务id,表示这个数据是由哪个事务生成的。 trx_id是必需的,占用 6 个字节。roll_pointer:
这条记录上一个版本的指针。roll_pointer 是必需的,占用 7 个字节NULL值列表:用位图存储的。压缩行存储通过一种称为”Dynamic Prefix”的技术,动态地存储每一行的前缀信息和 NULL 列的位图。这使得它可以更加高效地存储具有大量 NULL 列的行。
mysql读取时的几个情况
脏读:读到其他事务未提交的数据;
不可重复读:前后读取的数据不一致;
幻读:前后读取的记录数量不一致。
1
2
3
4
5不可重复读的重点是修改,幻读的重点在于新增或者删除。
例1(同样的条件, 你读取过的数据, 再次读取出来发现值不一样了 ):事务1中的A先生读取自己的工资为 1000的操作还没完成,事务2中的B先生就修改了A的工资为2000,导致A再读自己的工资时工资变为 2000;这就是不可重复读。
例2(同样的条件, 第1次和第2次读出来的记录数不一样 ):假某工资单表中工资大于3000的有4人,事务1读取了所有工资大于3000的人,共查到4条记录,这时事务2 又插入了一条工资大于3000的记录,事务1再次读取时查到的记 录就变为了5条,这样就导致了幻读。
脏读: A事务读取到了B事务未提交的内容,而B事务后面进行了回滚.
不可重复读: 当设置A事务只能读取B事务已经提交的部分,会造成在A事务内的两次查询,结果竟然不一样,因为在此期间B事务进行了提交操作.
幻读: A事务读取了一个范围的内容,而同时B事务在此期间插入了一条数据.造成”幻觉”.
mysql四种隔离级别
- Serializable (串行化) :可避免脏读、不可重复读、幻读的发生。
- Repeatable read (可重复读) :可避免脏读、不可重复读的发生。
- Read committed (读已提交) :可避免脏读的发生。
- Read uncommitted (读未提交) :最低级别,任何情况都无法保证。
SQL查看隔离级别:
1 |
|
生产环境数据库一般用的什么隔离级别呢?
生产环境大多使用RC(读已提交),
1 | 缘由一:在可重复读RR隔离级别下,存在**间隙锁**,导致出现死锁的几率比RC大的多! |
InnoDB的默认隔离级别:可重复读,不能避免幻读
多版本并发控制协议MVCC(Multi- Version Concurrency Control)
索引
https://zhuanlan.zhihu.com/p/340593296
什么是索引
索引是存储引擎用于提高数据库表的访问速度的一种数据结构。它可以比作一本字典的目录,可以帮你快速找到对应的记录。
索引一般存储在磁盘的文件中,它是占用物理空间的。
索引的分类(按字段特性)
- 主键索引:primary key,在创建表的时候一起创建,一张表最多只有一个主键索引,索引列的值不允许有空值。
1
2
3
4
5
6create table A(
x int primary key,
//或
x int,
primary key(x) using BTREE
);
建表后,创建主键索引CREATE INDEX a ON tableA(a);
再将其添加主键约束ALTER TABLE tableA ADD CONTRAINT id PRIMARY KEY
如果仅改一个主键ALTER TABLE tableA ADD PRIMARY KEY(a)
- 唯一索引:unique key建立在 UNIQUE 字段上的索引,一张表可以有多个唯一索引,索引列的值必须唯一,但是允许有空值。
1
2
3
4create table A{
x int unique key,
unique key(x)
}
- 建表后,创建唯一索引
create UNIQUE INDEX index_name ON table_name(index_column_1,index_column_2,...);
普通索引/二级索引:
1
CREATE INDEX idx on tableA(a,b,x,y);
前缀索引: 对字符类型字段的前几个字符建立的索引,而不是在整个字段上建立的索引
1
2
3
4CREATE TABLE tableA(
a varchar(255),
INDEX(a(10))//字符串前10个字符匹配。
);
【面试考点】联合索引如何使用的
指按sql里从左到右的顺序去匹配,查询条件中存在与联合索引中最左侧字段相匹配的字段,则就会使用该字段过滤一批数据,直至联合索引中全部字段匹配完成
失效的情况
如果有abc索引,可以支持查找时的 a/b/c/ac/cba(打乱),不支持bc
- 联合索引范围查询
联合索引的最左匹配原则会一直向右匹配直到遇到「范围查询」就会停止匹配。也就是范围查询的字段可以用到联合索引,但是在范围查询字段的后面的字段无法用到联合索引。
【例子】
1 | ```select * from tableA where a>= 10 and b=2;```的区别: |
B+ 树的叶子节点形成了一个有序链表,这使得范围查询的效率非常高,因为相邻的元素会被存储在相邻的位置,可以在一个或者很少几个相邻的节点中找到所有需要的数据。
B+ 树的叶子节点包含了所有的数据记录,这意味着每次查找都可以直接定位到具体的数据行,而不需要额外的中间层节点来获取实际数据。
1 | - 支持多级索引 |
举例来说,假设我们有一个三级索引 (a, b, c),那么:
第一级索引以 a 为键构建一颗 B+ 树,每个节点中存储 b 的值以及指向第二级索引的指针。
第二级索引以 b 为键构建一颗 B+ 树,每个节点中存储 c 的值以及指向第三级索引的指针。
第三级索引以 c 为键构建一颗 B+ 树,叶子节点中存储了对应的数据记录。
这样的设计使得在多级索引中,每一层都能帮助缩小搜索范围,从而提高查询效
其中,叶子节点和非叶子节点的数据结构是一样的,区别在于,叶子节点存放的是实际的行数据,而非叶子节点存放的是主键和页号。
1 | ## 【面试】 索引失效的情况 |
explain结果的Extra列为Using index,查询的列被索引覆盖,并且where筛选条件符合最左前缀原则,通过索引查找就能直接找到符合条件的数据,不需要回表查询数据。
1 |
|
在插入数据的时候,会为被 AUTO_INCREMENT 修饰的字段加上轻量级锁,然后给该字段赋值一个自增的值,就把这个轻量级锁释放了,而不需要等待整个插入语句执行完后才释放锁。
应用场景
行锁
记录锁 Record Lock,仅仅把一条记录锁上;
间隙锁 Gap Lock,锁定一个范围,但是不包含记录本身;间隙锁的意义只在于阻止区间被插入
临键锁 Next-Key Lock:Record Lock + Gap Lock 的组合,锁定一个范围,并且锁定记录本身。
- 【普通的select没有行锁】普通的 select 是不会加行级锁的,普通的 select 语句是利用 MVCC 实现一致性读,是无锁的。
记录锁 Record Lock
记录锁分为S锁和X锁。 - 当一个事务对一条记录加了 S 型记录锁后,其他事务也可以继续对该记录加 S 型记录锁(S 型与 S 锁兼容),但是不可以对该记录加 X 型记录锁(S 型与 X 锁不兼容);
- 当一个事务对一条记录加了 X 型记录锁后,其他事务既不可以对该记录加 S 型记录锁(S 型与 X 锁不兼容),也不可以对该记录加 X 型记录锁(X 型与 X 锁不兼容)。
间隙锁 Gap Lock
只存在于可重复读隔离级别,目的是为了解决可重复读隔离级别下幻读的现象。 - 对间隙加锁是为了防止插入/删除的时候出现幻读
- 间隙锁之间是兼容的,即两个事务可以同时持有包含共同间隙范围的间隙锁,并不存在互斥关系,因为间隙锁的目的是防止插入幻影记录而提出的。
临键锁 Next-key Lock
理解为一个范围的间隙锁
【面试题】MYSQL怎么加锁
- 【加行锁】在查询时对记录加行级锁,这两种查询会加锁的语句称为锁定读。
1
2
3
4
5
6
7
8
9
10
11//对读取的记录加共享锁(S型锁)
select ... lock in share mode;
//对读取的记录加独占锁(X型锁)
select ... for update;
//对操作的记录加独占锁(X型锁)
update table .... where id = 1;
//对操作的记录加独占锁(X型锁)
delete from table where id = 1;
上面这两条语句必须在一个事务中,因为当事务提交了,锁就会被释放,所以在使用这两条语句的时候,要加上 begin 或者 start transaction 开启事务的语句。
普通查询,没有使用索引的话,会导致什么情况?
没有使用索引字段作查询条件的话,导致扫描是全表扫描。那么,每一条记录的索引上都会加 临键(NK)锁,这样就相当于锁住的全表,这时如果其他事务对该表进行增、删、改操作的时候,都会被阻塞。
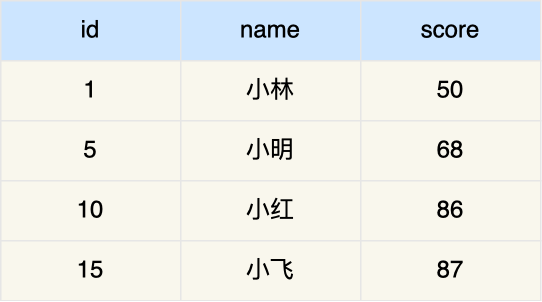
- 如果在 update 语句的 where 条件没有使用索引,就会全表扫描,于是就会对所有记录加上 next-key 锁(记录锁 + 间隙锁),相当于把整个表锁住了。
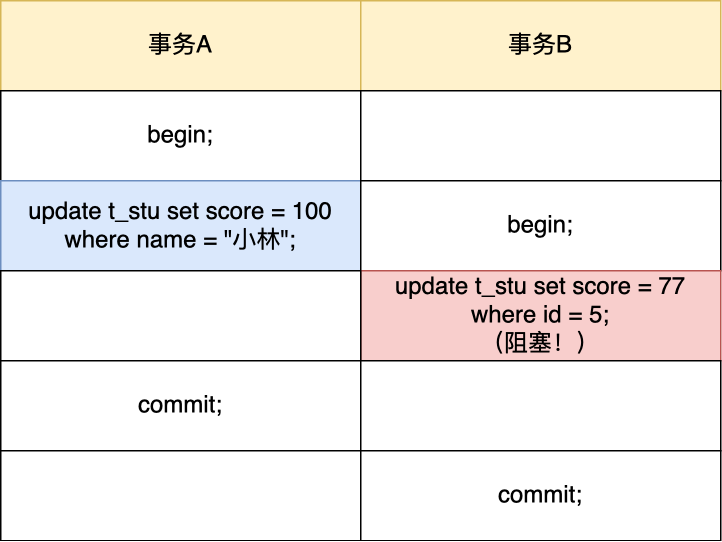
那 update 语句的 where 带上索引就能避免全表记录加锁了吗?
关键还得看这条语句在执行过程种,优化器最终选择的是索引扫描,还是全表扫描,如果走了全表扫描,就会对全表的记录加锁了。
update 没加索引,加的是表锁还是行锁
对每一行都加了NK锁,就锁了整张表。
避免全表锁定
将 MySQL 里的 sql_safe_updates 参数设置为 1,开启安全更新模式。
update 语句必须满足如下条件之一才能执行成功:
1
2
3使用 where,并且 where 条件中必须有索引列;
使用 limit;
同时使用 where 和 limit,此时 where 条件中可以没有索引列;delete 语句必须满足以下条件能执行成功:
1
2
3同时使用 where 和 limit,此时 where 条件中可以没有索引列;
另外:如果 where 条件带上了索引列,但是优化器最终扫描选择的是全表,而不是索引的话,我们可以使用 FORCE INDEX([index_name]) 可以告诉优化器使用哪个索引,以此避免有几率锁全表带来的隐患。
MySQL 记录锁+间隙锁可以防止删除操作而导致的幻读吗?【可以】
插入意向锁
插入意向锁的生成时机:
每插入一条新记录,都需要看一下待插入记录的下一条记录上是否已经被加了间隙锁,如果已加间隙锁,此时会生成一个插入意向锁,然后锁的状态设置为等待状态(PS:MySQL 加锁时,是先生成锁结构,然后设置锁的状态,如果锁状态是等待状态,并不是意味着事务成功获取到了锁,只有当锁状态为正常状态时,才代表事务成功获取到了锁),现象就是 Insert 语句会被阻塞。
三大日志
binlog,归档日志,逻辑日志,属于Server层,与引擎无关
保证一致性C;用于数据库的数据备份、主备、主主、主从复制
- 事务执行过程中,先把日志写到binlog cache,事务提交的时候,再把binlog cache写到binlog文件中,事务一次性写入,后台给一个线程去写
三种模式:statement、row和mixed.
- statement模式下,记录单元为语句.即每一个sql造成的影响会记录.由于sql的执行是有上下文的,因此在保存的时候需要保存相关的信息,同时还有一些使用了函数之类的语句无法被记录复制.
- row级别下,记录单元为每一行的改动,基本是可以全部记下来但是由于很多操作,会导致大量行的改动(比如alter table),因此这种模式的文件保存的信息太多,日志量太大.
- mixed. 一种折中的方案,普通操作使用statement记录,当无法使用statement的时候使用row.
show master status
在my.ini文件中 查看bin_log文件位置
redolog:宕机恢复数据,物理日志
Redo Log记录的是新数据的备份。
保证持久性D
- 查询一条记录,会从硬盘把一页的数据加载出来,加载出来的数据叫数据页,会放入到 Buffer Pool 中
- 后续的查询都是先从 Buffer Pool 中找,没有命中再去硬盘加载,减少硬盘 IO 开销,提升性能
- 更新表数据的时候,也是如此,发现 Buffer Pool 里存在要更新的数据,就直接在 Buffer Pool 里更新,然后会把修改内容记录到redologbuffer里,接着刷盘到 redo log 文件里
undolog:回滚,缺点-写操作较多
在操作任何数据之前,首先将数据备份到一个地方(这个存储数据备份的地方称为UndoLog)。然后进行数据的修改。如果出现了错误或者用户执行了ROLLBACK语句,系统可以利用Undo Log中的备份将数据恢复到事务开始之前的状态。
保证原子性A
- 所有事务进行的修改都会先记录到这个回滚日志中,然后再执行相关的操作
- MVCC 的实现依赖于:隐藏字段、Read View、undo log。在内部实现中,InnoDB 通过数据行的 DB_TRX_ID 和 Read View 来判断数据的可见性,如不可见,则通过数据行的 DB_ROLL_PTR 找到 undo log 中的历史版本。每个事务读到的数据版本可能是不一样的,在同一个事务中,用户只能看到该事务创建 Read View 之前已经提交的修改和该事务本身做的修改
刷盘时机
- 每条 redo 记录由“表空间号+数据页号+偏移量+修改数据长度+具体修改的数据”组成
https://gitee.com/mydb/interview
如何做增量备份
- mysqldump 做一个全备
- mysqlbinlog 做一个增量备份
innodb使用自增ID当主键【顺序添加,uuid插入值会造成页面的碎片和不紧凑的索引结构】
如果表使用自增主键,那么每次插入新的记录,记录就会顺序添加到当前索引节点的后续位置,当一页写满,就会自动开辟一个新的页。如果使用非自增主键(如果身份证号或学号等),由于每次插入主键的值近似于随机,因此每次新纪录都要被插到现有索引页得中间某个位置, 频繁的移动、分页操作造成了大量的碎片,得到了不够紧凑的索引结构,后续不得不通过OPTIMIZE TABLE(optimize table)来重建表并优化填充页面
MyISAM和InnoDB使用B+树做索引,区别是什么【innodb使用聚簇,myisam使用非聚簇】
- Innodb的聚簇:数据在叶子节点有序存放,非叶子存放key和页号,也就是一棵B+树的索引文件本身就可以是数据文件,找到了索引就找到了对应的行数据。
- 叶节点存key和data。data域存放的是数据记录的地址,在索引检索的时候,首先按照B+Tree搜索算法搜索索引,如果指定的key存在,则取出其data域的值,然后以data域的值为地址读取相应的数据记录,这被称为“非聚簇索引”
mysql自增主键不连续的情况原因有三个:
1) 唯一键冲突
2) 事务回滚
3) insert…select的时候会出现主键id每次双倍分配导致主键id跳过的问题
高并发场景下,如何安全修改同一行数据
- 悲观锁,innodb的事务支持加行锁
- 乐观锁,每次修改时先判断版本号是否一直,如果更改了就返回失败/重试,使用版本号机制,或者CAS算法实现
- CAS算法
select …for update语句是我们经常使用手工加锁语句。
用来锁定特定的行(如果有where子句,就是满足where条件的那些行)。当这些行被锁定后,其他会话可以选择这些行,但不能更改或删除这些行,直到该语句的事务被commit语句或rollback语句结束为止
超大数据
如果mysql limit加载超多10000,如何解决
- 如果id连续,分离出来几个范围查找
- 利用子查询优化超多分页场景。(先快速定位需要获取的id段,然后再关联)
- order by id 10000,10
- 更改业务,一般不需要那么多数量
千万数据,可以用分库分表优化表结构
- 分表方案(水平分表,垂直分表,切分规则hash等)
- 分库分表一些问题(事务问题?跨节点Join的问题)
- 分库分表中间件(Mycat,sharding-jdbc等)
- 解决方案(分布式事务等如何做)
【思格】简述count(1)、count(*)与count(列名)的执行区别 ?
count(*):包括了所有的列,相当于行数,在统计结果的时候, 不会忽略列值为NULL
count(1):包括了忽略所有列,用1代表代码行,在统计结果的时候, 不会忽略列值为NULL
count(列名):只包括列名那一列,在统计结果的时候,会忽略列值为空(这里的空不是只空字符串或者0,而是表示null)的计数, 即某个字段值为NULL时,不统计。
执行效率上:
列名为主键,count(列名)会比count(1)快
列名不为主键,count(1)会比count(列名)快
如果表多个列并且没有主键,则 count(1) 的执行效率优于 count()
如果有主键,则 select count(主键)的执行效率是最优的
如果表只有一个字段,则 select count()最优。

