ok
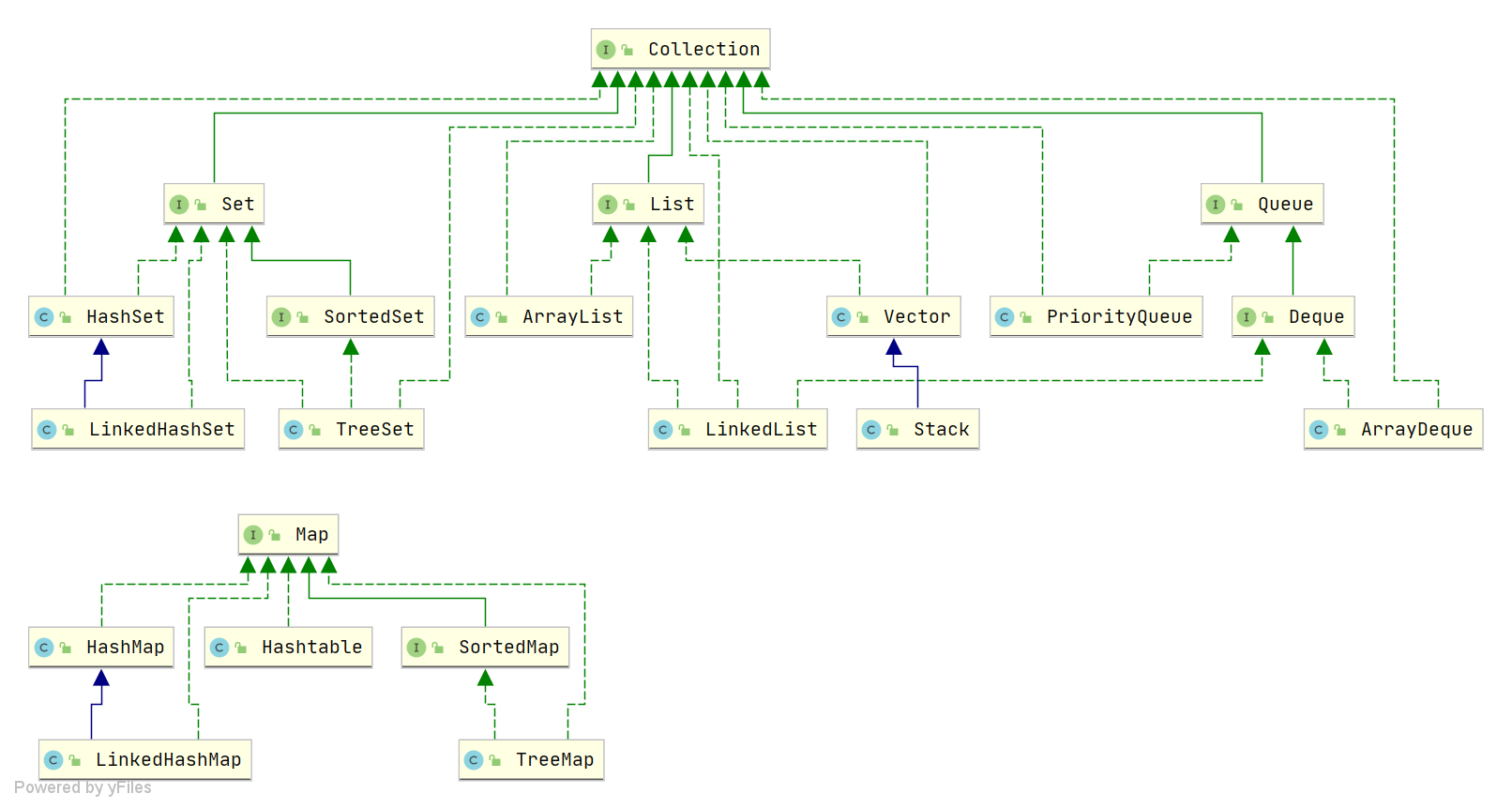
Collection
- List
- ArrayList: Object[]
- Vector: Object[]
- LinkedList: 双向链表
- Set
- HashSet(无序,唯一): 底层采用 HashMap 来保存元素-
- LinkedHashSet: HashSet 的子类,通过 LinkedHashMap 来实现的
- TreeSet(有序,唯一): 红黑树(自平衡的排序二叉树)
- Queue
- HashMap
- 开始是链表,链表长度大于阈值8,进行扩容,当容量大于64时,变成红黑树
- LinkedHashMap
- 在HashMap的基础上,增加了一条双向链表,保持KV的插入顺序
- Hashtable
- 数组+链表组成的,数组是 Hashtable 的主体,链表则是主要为了解决哈希冲突而存在的
- TreeMap:红黑树
TIPs
- 保证线程安全的手段?Concurrent修饰的Map等
- 持续更新
List实现
ArrayList 和 Array 的区别
- 一个动态数组和静态数组
- 区别类似于go语言和python的slice实现
- 声明时不需要指定大小,动态扩容
- 支持泛型
- 支持插入、更改、删除
【面试题】说说ArrayList的扩容机制
ArrayList 和 Vector 的区别
- ConcurrentHashMap、CopyOnWriteArrayList等,
- 或者手动实现线程安全的方法来提供安全的多线程操作支持。
ArrayList 可以添加 null 值吗?
ArrayList 中可以存储任何类型的对象,包括 null 值。不过,不建议向ArrayList 中添加 null 值, null 值无意义,会让代码难以维护比如忘记做判空处理就会导致空指针异常。
Set实现
Comparable 和 Comparator 的区别:都是用于排序
- Comparable 接口实际上是出自 java.lang 包 它有一个 compareTo(Object obj)方法用来排序
- Comparator 接口实际上是出自 java.util 包 它有一个 compare(Object obj1, Object obj2)方法用来排序
- 需要对一个集合使用自定义排序时,我们就要重写compareTo()方法或compare()方法
Queue实现
Queue 与 Deque 的区别
- Queue是单端队列,遵循先进先出(FIFO)规则
- Deque 是双端队列,在队列的两端均可以插入或删除元素
PriorityQueue实现:默认最小二叉堆
- P利用了二叉堆的数据结构来实现的,底层使用可变长的数组来存储数据
- PriorityQueue 通过堆元素的上浮和下沉,实现了在 O(logn) 的时间复杂度内插入元素和删除堆顶元素。
- PriorityQueue 是非线程安全的,且不支持存储 NULL 和 non-comparable 的对象。
- PriorityQueue 默认是小顶堆,但可以接收一个 Comparator 作为构造参数,从而来自定义元素优先级的先后。
- PriorityQueue 在面试中可能更多的会出现在手撕算法的时候,典型例题包括堆排序、求第 K 大的数、带权图的遍历等,所以需要会熟练使用才行。
手撕一个priorityqueue
1 |
BlockingQueue
- 支持当队列没有元素时一直阻塞,用于生产者消费者模型
- 生产者线程会向队列中添加数据,而消费者线程会从队列中取出数据进行处理
ArrayBlockingQueue 和 LinkedBlockingQueue 是 Java 并发包中常用的两种阻塞队列实现
- 都线程安全,Array底层用的固定数组,Linked底层用的链表,也是扩容机制
- ArrayBlockingQueue 生产和消费用的是同一个锁
- LinkedBlockingQueue 生产用putLock,消费用的takelock,防止生产者和消费者线程之间的锁争夺
Map实现
HashMap 和 Hashtable(淘汰) 的区别
HashMap 是线程不安全的,线程安全版ConcurrentHashMap
Hashtable 是线程安全的
HashMap 可以存储 null 的 kv,但 null 作为键只能有一个,null 作为值可以多个
Hashtable 不允许有 null 键和 null 值,否则会抛NullPointerException
HashMap的构造函数以及扩容函数1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
HashSet
- HashSet如何检查重复的: 底层使用HashMap
1
2
3public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
HashMap的底层实现
- hash()函数,拉链法解决冲突
1
2
3
4
5
6
7static final int hash(Object key) {
int h;
// key.hashCode():返回散列值也就是hashcode
// ^:按位异或
// >>>:无符号右移,忽略符号位,空位都以0补齐
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
HashMap线程不安全
- jdk1.7前,HashMap 扩容时会造成死循环和数据丢失的问题
- jdk1.8后,多个kv可能会被分配到同一个桶(bucket),并以链表或红黑树的形式存储。多个线程对 HashMap 的 put 操作会导致线程不安全,具体来说会有数据覆盖的风险。
HashMap遍历
https://mp.weixin.qq.com/s/zQBN3UvJDhRTKP6SzcZFKw - 结论,尽量使用 entrySet 来实现 Map 集合的遍历
- 不能再在遍历中使用集合 map.remove() 来删除数据,这是非安全的操作方式
- 但可以使用迭代器的 iterator.remove() 的方法来删除数据,这是安全的删除集合的方式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51public class HashMapTest {
public static void main(String[] args) {
// 创建并赋值 HashMap
Map<Integer, String> map = new HashMap();
map.put(1, "Java");
map.put(2, "JDK");
map.put(3, "Spring Framework");
map.put(4, "MyBatis framework");
map.put(5, "Java中文社群");
// 迭代器 entrySet 遍历
Iterator<Map.Entry<Integer, String>> iterator =
map.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<Integer, String> entry = iterator.next();
System.out.println(entry.getKey());
System.out.println(entry.getValue());
}
// 迭代器 keySet 遍历
Iterator<Integer> iterator = map.keySet().iterator();
while(iterator.hasNext()){
Integer key = iterator.next();
System.out.println(key);
System.out.println(map.get(key));
}
// for-each 遍历 entrySet()
for (Map.Entry<Integer, String> entry : map.entrySet()) {
System.out.println(entry.getKey());
System.out.println(entry.getValue());
}
// for-each 遍历 keySet()
for (Integer key : map.keySet()) {
System.out.println(key);
System.out.println(map.get(key));
}
// Lambda表达式
map.forEach((key, value) -> {
System.out.println(key);
System.out.println(value);
});
// Streams API 单线程
map.entrySet().stream().forEach((entry) -> {
System.out.println(entry.getKey());
System.out.println(entry.getValue());
});
// Streams API 多线程
map.entrySet().parallelStream().forEach((entry) -> {
System.out.println(entry.getKey());
System.out.println(entry.getValue());
});
}
}

